GIF
01
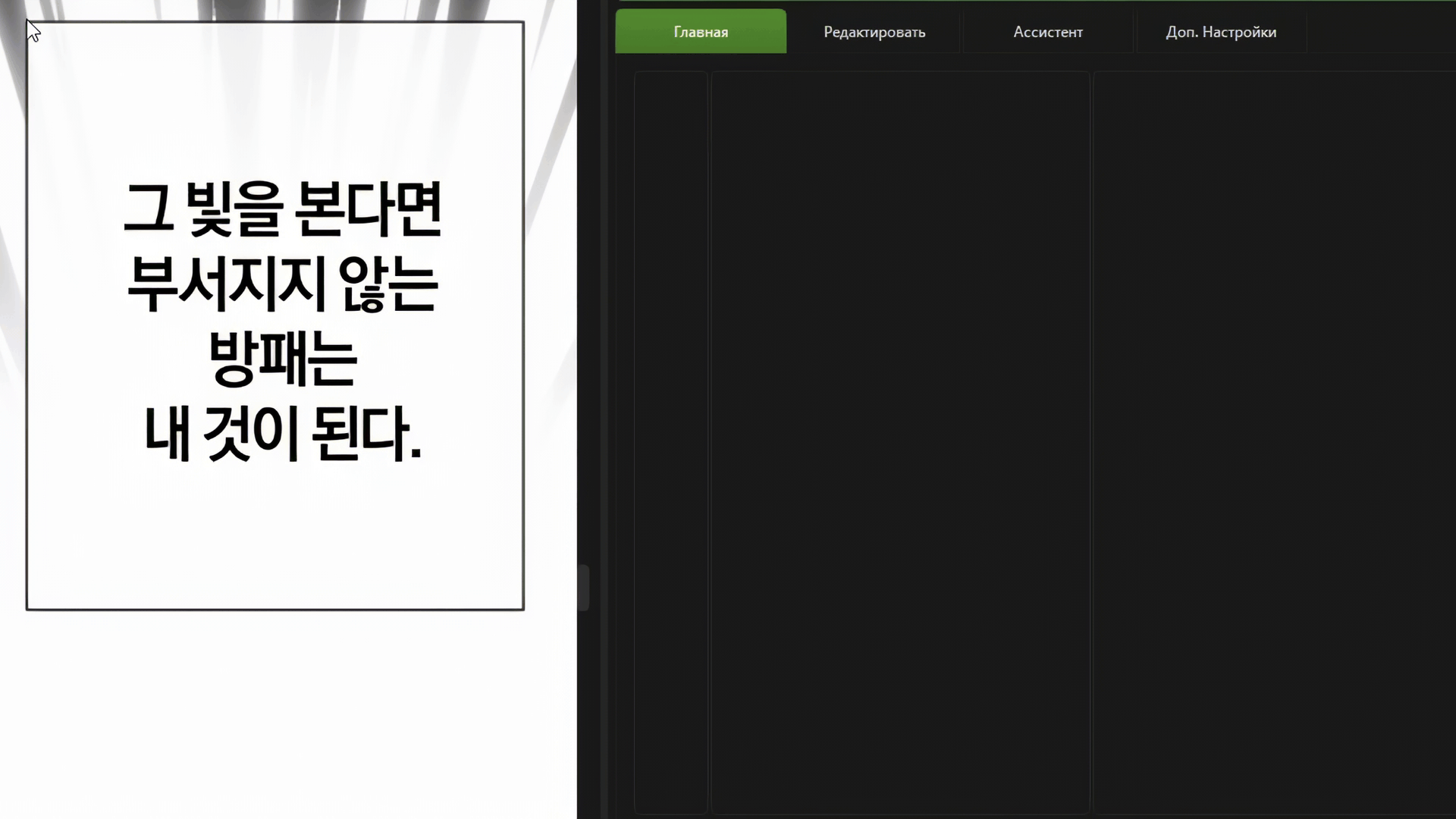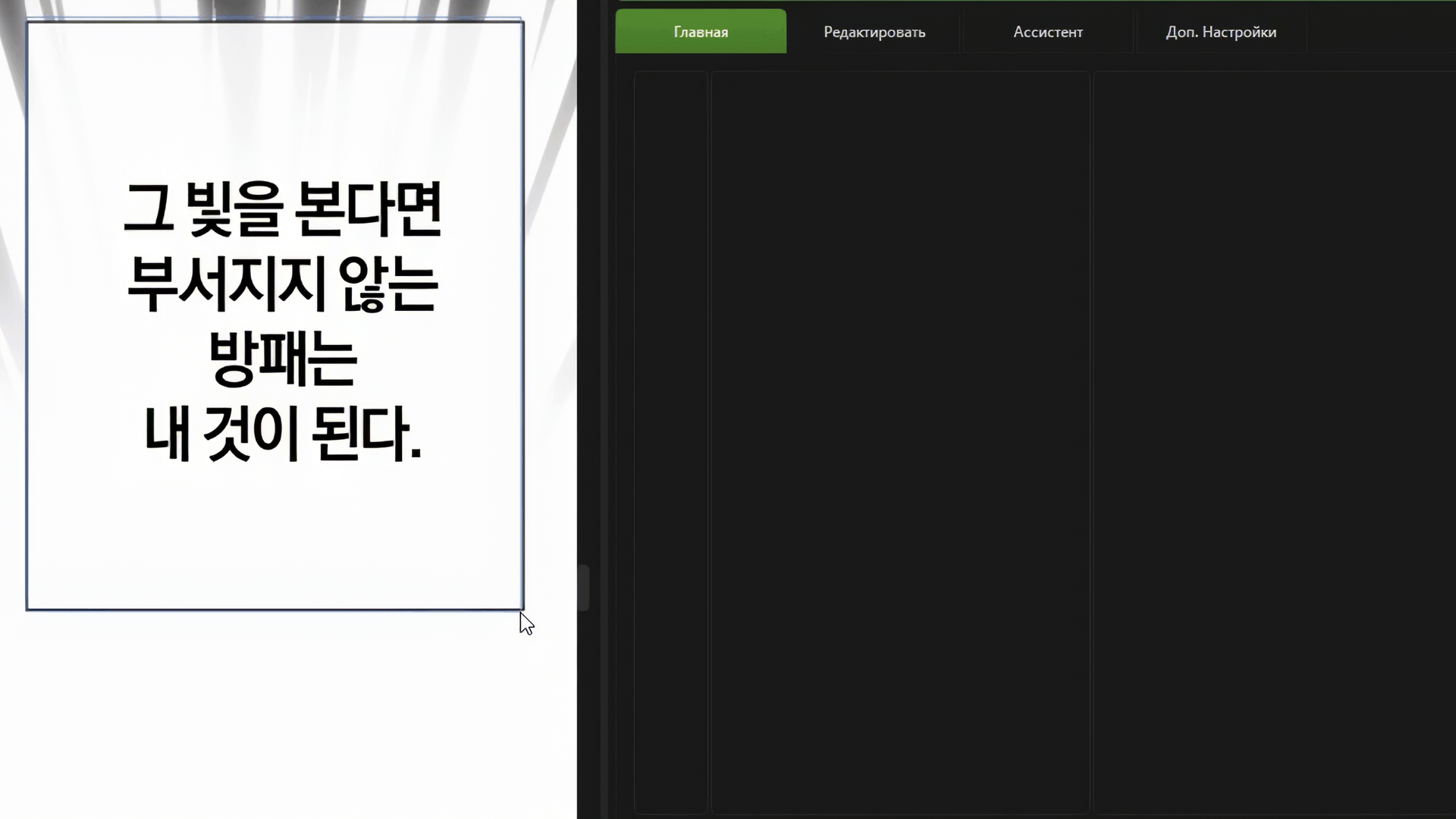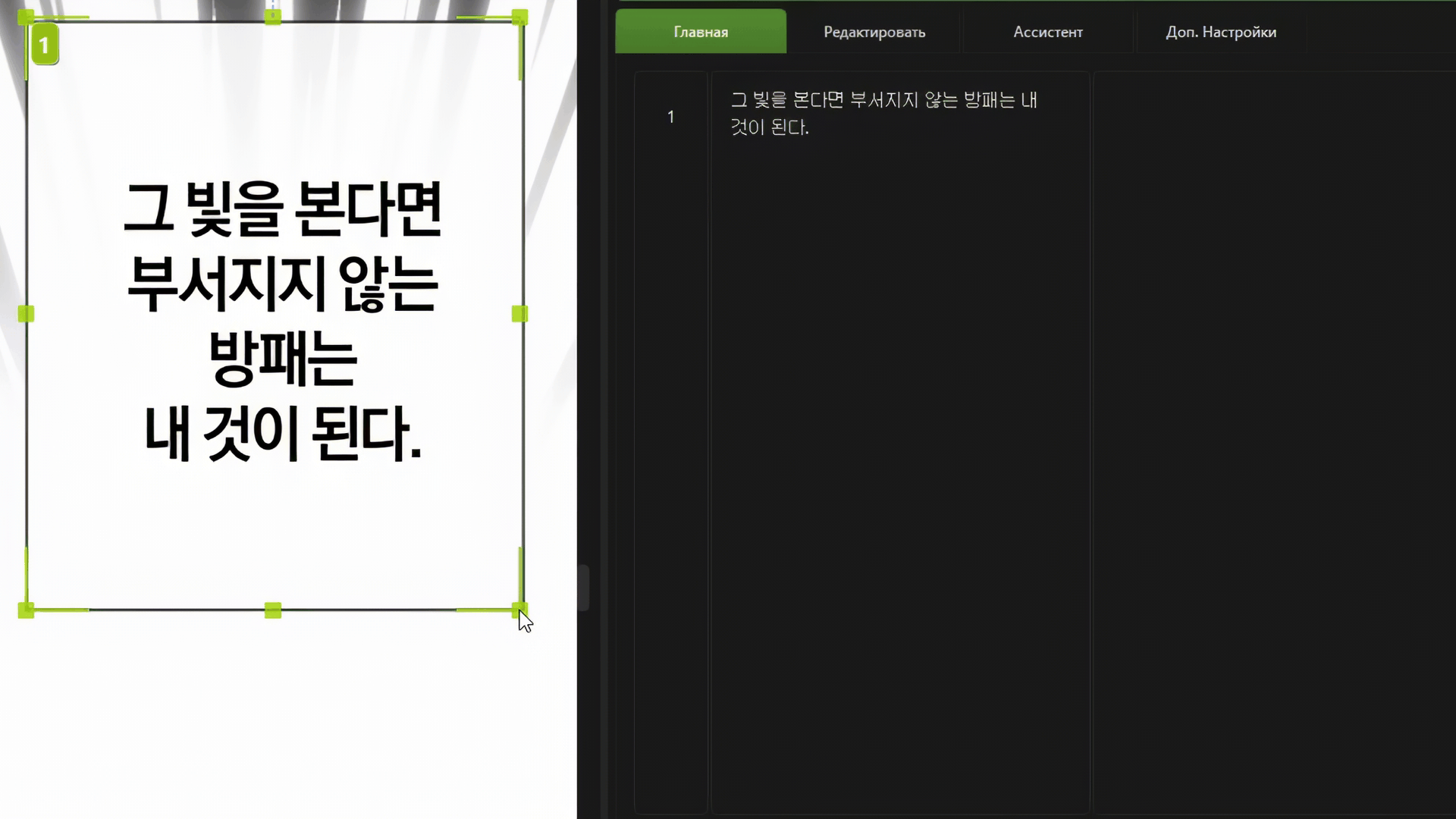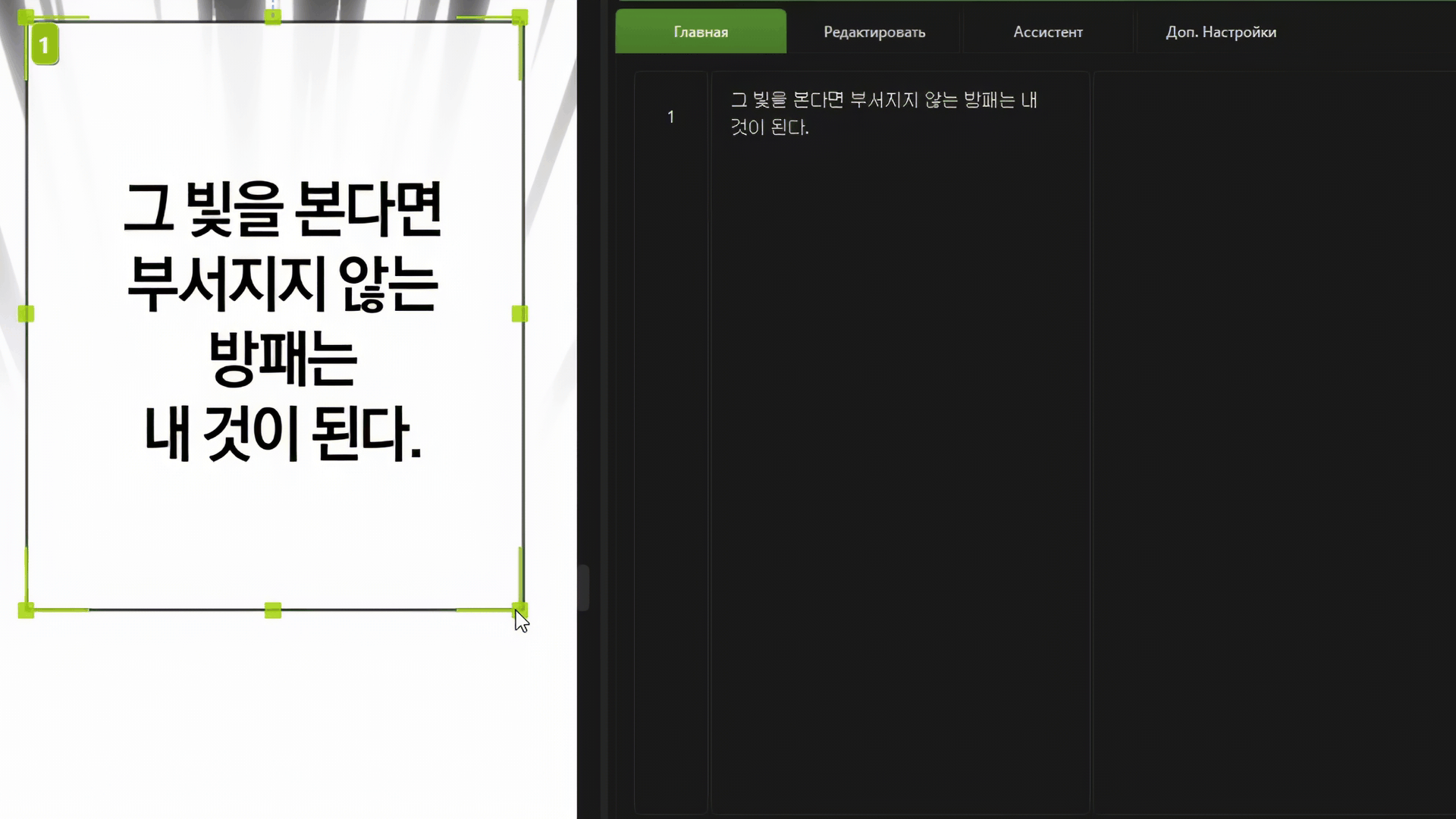
Извлечение и перевод
Извлекайте и переводите с Английского, Корейского, Японского, Китайского и других языков.
Извлекайте и переводите с Английского, Корейского, Японского, Китайского и других языков.

Используйте локальные и облачные модели для очистки сканов.
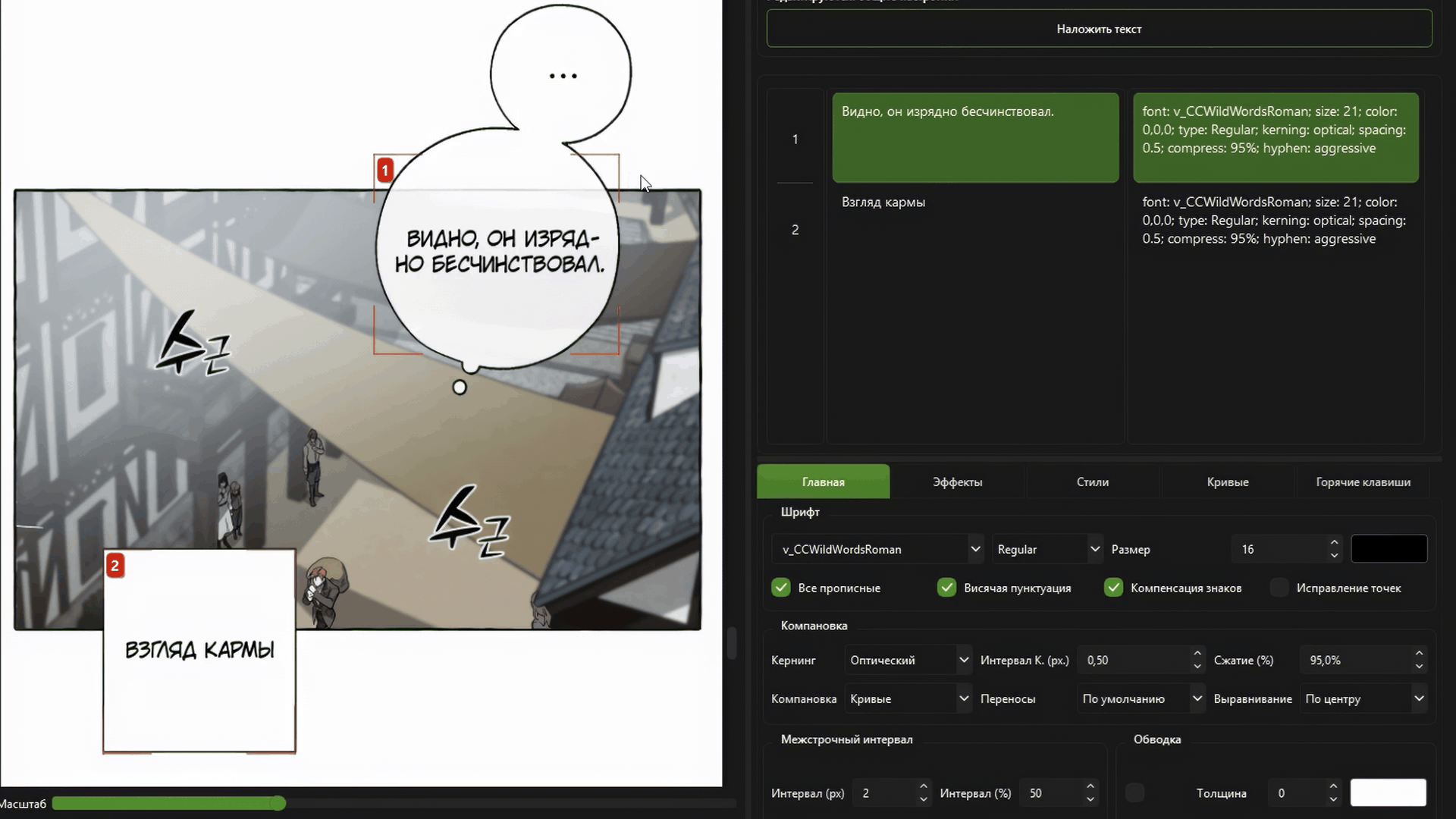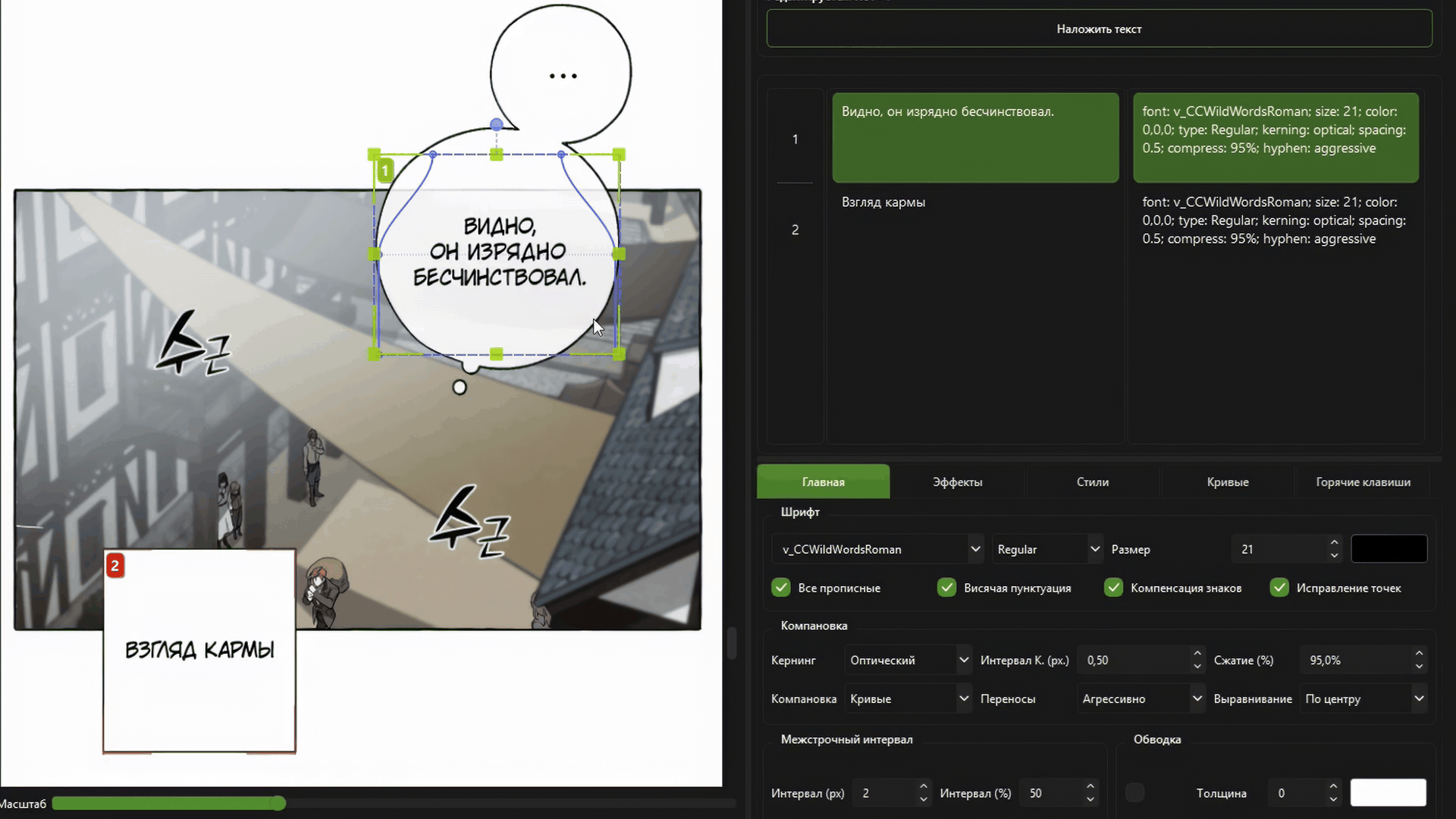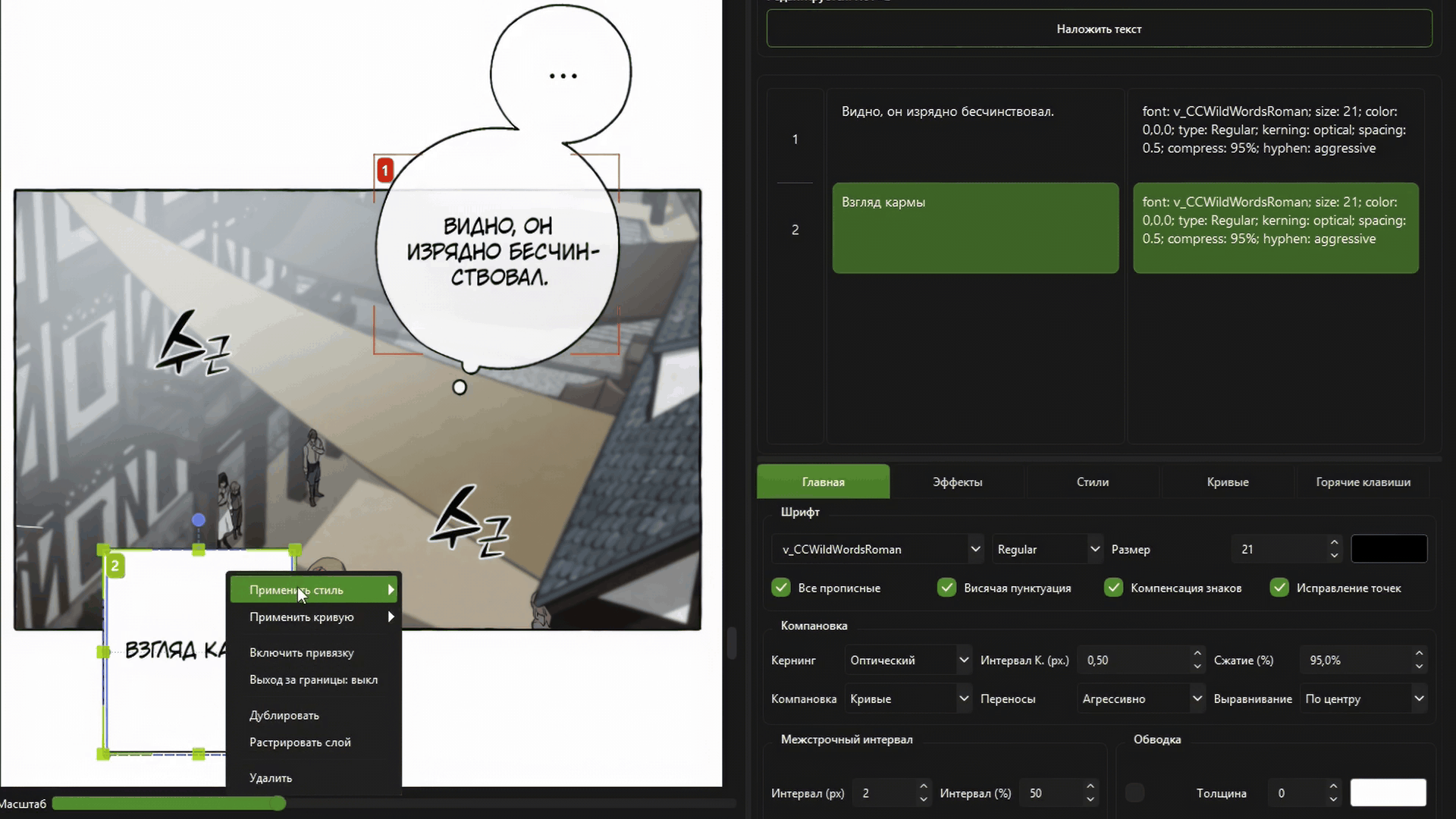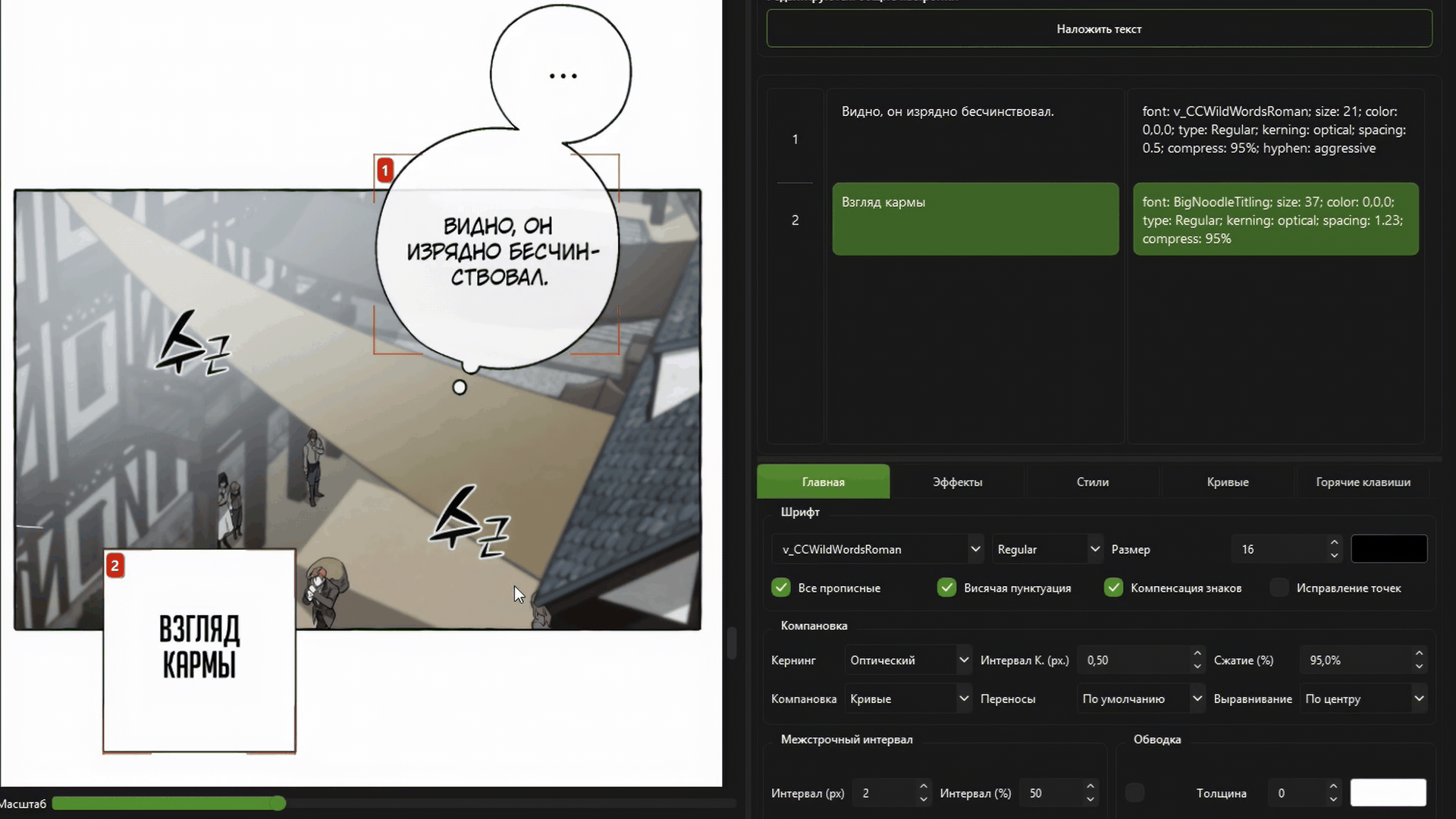
Полноценный оптический кернинг и авто-компоновка текста.
Минимальные требования: Windows 10 64-bit, 6 GB RAM, 12 GB свободного места на диске, процессор AMD FX-6300 или Intel Core i3-4130 (или новее).
Рекомендованные требования: Windows 10/11 64-bit, 12 GB RAM, 12 GB свободного места на диске, процессор Intel Core i5-8400 или AMD Ryzen 5 2600. Для ускорения обработки рекомендуется любая видеокарта с поддержкой CUDA (например, GTX 1050 Ti или выше).
ВНИМАНИЕ: Работа всего функционала не гарантируется на интегрированных видеокартах и дискретных видеокартах от AMD, а также видеокартах NVIDIA RTX 5000 серии!